Today your pal and mine, Lex Friedman, released episode two of Your Daily Liss. Which is to say, I was a guest on Your Daily Lex, episode #1048.
Lex is traveling at the moment, and has both pre-recorded episodes of YDL, as well as had guests like me sit in.
Your Daily Lex is far more fun and interesting than a daily podcast about a middle-aged white dude should be; here’s hoping I didn’t besmirch the podcast’s good name. But even if I did, a little under five minutes won’t kill you. 😏
This week I was also on Clockwise. On the episode, I joined Aleen Simms, Dan Moren, and Mikah Sargent to discuss Apple’s recently-released public betas of 𝓍OS 27, how we read for pleasure, embracing multicolored smart lighting, and how we prepare for disaster both physically and digitally.
I’ve become a prolific Goodreads user over the last several years. Reading a book is a commitment, and I like to record the completion of that commitment. Goodreads does that for me.
Goodreads also lets you rate books, on a ☆☆☆☆☆ → ★★★★★ scale. My personal rating system seems to be… stingier… than most:
- ★☆☆☆☆ A truly terrible book that I regret reading.
- ★★☆☆☆ A book that was not good, but was worth finishing.
- ★★★☆☆ The default rating. Enjoyable.
- ★★★★☆ Above average. More than just enjoyable; worth recommending.
- ★★★★★ Truly excellent. One that made me think about things differently, and/or I would recommend to others without being solicited for a recommendation.
Of the 216 books I’ve read and logged on Goodreads, only five have earned ★★★★★. Of those, two were books about Apple, one was the absolute classic The Power Broker[1]. The other two were Upgrade and Project Hail Mary.
When I watched the film, I expected it to be a standard film treatment of a novel: the main points would be hit, but so much would be skipped. As it turns out, I don’t think that’s true at all. The film was astonishingly true to the novel, though particularly the last act got fast-forwarded quite a bit.
Last week, I was lucky enough to join Aleen Simms, Quinn Rose, Brian Warren and, of course, Jason Snell, to discuss the film on The Incomparable.
During the discussion, we discuss how the film stands as a film, how it compares and contrasts with the book, and how much we fell in love with Rocky. Forgive the spoiler, but we were all pretty effusive, and I think that comes through in the episode.
I had a blast recording this one, and if you’re a fan of the book or the film, I think you’ll have a blast listening.
I feel like I rarely read non-fiction, but oddly, three of my five ★★★★★ books are non-fiction books. I stand by that I vastly prefer fiction to non-fiction, but, uh, apparently I pick my non-fiction reads well? ↩
Callsheet nears its third birthday, and as such, it’s time for me to post another Year in Review. I started doing this at the end of year one, and repeated it last year. I started making these posts mostly as a marketing/retention exercise. However, they quickly became posts I’m also writing for me, to remind myself of all the progress I’ve made over the last year.
To begin, it’s worth noting that pricing remains the same as it was in 2023, when things seemed… quite a bit more stable. As I sit here now, I repeat what I said last year:
I’m not saying that I’m planning to raise prices, but I’m also not… not-saying that.
I am more convinced than ever that Callsheet is incredible value for money, even if it was stagnant. Which it very much was not!
Here’s what kept me busy for the last year:
2025.8
- Optionally show cast and crew credits in one list
- Fixed a race condition that could occasionally prevent Now Playing from working properly
- Fixed collection navigation (↑↓) not working properly when Callsheet was not in English
- Callsheet shows native-language search results where possible
- Fixed issue with shared TV episodes being off by 1
- Fixed issue that prevents duplicates in “Known For”
- Fixed rare issue with re-opening the TV episode you already have open by URL
- Fixed rare issue where release dates weren’t shown
- Fixed localization issue for French
- Add Finnish localization
2025.9
- Liquid Glass redesign
- New search affordance which lets you quickly swap between searching globally or searching the screen you’re on
- Moved Recent Searches to the Discover screen
- Moved Search History to the top toolbar
- When viewing a show or film, you can see a union of cast & crew credits
- Clearer “no results” messaging
- You can now swipe left-to-right on Search Results and return to Discover
- Callsheet is more aggressive about clearing Now Playing items that… are no longer playing
- Improvements to search results that contain curly quotes
- Scrolling longer views downward will dismiss the keyboard
- Bad data about a movie collection will no longer cause Callsheet to get confused
- Improvements when switching between lists
2025.10
- Discover sections can be toggled on or off in Persnickety Preferences
- Removed a large visual glitch on TV shows
- Improve the way Dynamic Type looks
- Tightened up Search History presentation on Discover
- Fix presentation for season carousel when Show Borders is enabled
- Fix wonky presentation of the Theme picker in Persnickety Preferences
2026.1
- Discover sections can now also be reordered in addition to added/removed
- For people, the role of
Selfcan now be filtered out via drop-down or context menu - TV shows will show approximate ages of cast/crew during the run where possible
- Added a context menu for Search History on Discover
- Visual tweaks to the search bar
- Allow for more than 100 pins in a list; Recents are limited to 100 and Search History to 50
- TV episodes released today show
Todayinstead of how many hours it’s been since midnight - Added a
More info…link to the integrations section - Fixed issue where opening a link in the system browser caused the search bar to disappear
- The
Upcomingsection for people is consistently ordered - Fix some occasional wonkiness with the search prompt when in the local search scope
- Movie collections now use chevrons instead of ↑↓ for better consistency
- Fixed the URL scheme
callsheet://activateInputwhich I accidentally broke - Keyboard dismisses interactively on Discover
- Fix issue where the subscribe button would flash
0for a moment when it was being hidden - Small tweaks to the Norwegian translation
- Prevent edge case where the paywall could be avoided by loading items by URL
- Reduce the size of the
URLSessioncache - Additional logging around Region Override
2026.2
- Fix bug where age calculations were not shown for movies > 20 years old
2026.3
- Improved Shortcuts support:
- Get Media
- Get Media Videos
- Get Pins
- Perform Search
- Search pagination via infinite scroll
- Japanese and Korean localizations
- You can now eliminate
Thanks(as you canSelf) in a person’s credits list - New Persnickety Preference for
Include Self & Thanks - Added place of birth as a popover when tapping on a person’s birth information
- Added death information for people who were on a show during one year of their lives, but have since passed (the [Ron Glass][rg] bug)
- Channels integration now works on IPv4-exclusive networks
- Fix edge case where
Selfcredits could slip through the filter - Fix edge case where popover for a person’s height wouldn’t show alternate units
- Fix edge case where search scope button would disappear
- Fix edge case where search via URL would perform a local rather than global search
- Tweak system spoiler settings presentation on iPad/Mac
- Performed audit on in-app purchase code mostly around gnarly edge cases
- Add some missing localizations
- Fix minor issues in Italian and Australian localizations
2026.4
- All-new iPad landscape layout that is vastly improved; this also applies to visionOS and macOS
- New integration for Jellyfin, so you can see your Jellyfin information in Now Playing
- People’s names and role/jobs are now copyable via context menu
- More clever/region-appropriate localizations for
Johnny Appleseed&Botanistexamples in Spoiler Settings Hide Spoilers…button allows tapping the whole button, rather than just the text- No longer truncate titles/names in Discover wherever possible
- Fix edge case where navigating a movie collection would fail
2026.5
- Pins are now cached, hopefully avoiding iCloud issues being show-stoppers
- Movie/episode details of items you’re currently playing will show progress meters and indicate end time rather than runtime
- Bifurcate Plex connections into two approaches: legacy/Passive, and new Active connections
- Errors are far less of an eyesore
- On cold start, Discover layouts should dance around far less
- Better handle missing posters on Discover
- When copying an error report, the deep link URL is included
- When viewing a show in Channels, jump to the episode when you tap on the item in Now Playing
- Fix issue where Callsheet eagerly showed a
cancellederror when it shouldn’t - Fix scroll position when switching between Cast & Crew on iPad/Mac
- Fix edge case where Callsheet would consistently lose Discover section settings and/or Region Override and/or Language Override
- Fix edge case where Callsheet was showing people as pinned who… weren’t pinned
- Fix edge case where bonus free searches could be lost
- Fixes for Australian localization
2026.6
- Now Playing titles are hoisted to the top of Known For when viewing people
- Plex Active connections now let you choose which of your servers to bind to
- Improve contrast behind Now Playing progress bars
- Backing from Search Results → Recent Searches clears the search box
- Age ranges are redacted for shows where episode counts are hidden
- Some improved logging for Active Plex connections
- Active Plex connections no longer hang during setup when Callsheet is set to use the system browser
- ⌘F works again on iPad/macOS
This is an immense amount of progress for just one person in just one year. I’m very proud of where Callsheet is today. If you’re an existing subscriber, I hope you’ll consider renewing. If you’re not, you should give Callsheet a chance; I think you’ll like it.
Back in March, Rivian’s Chief Software Officer, Wassym Bensaid, was interviewed by the excellent Nilay Patel for Decoder. If you’re not a Decoder listener, you should be. If you’re not a subscriber of The Verge, you should be. But that’s not what I’m here to talk about.
In this interview — which I greatly enjoyed! — Nilay grills Wassym on all manner of issues. The whole time, though, I was waiting for one topic: CarPlay.
CarPlay is a way to interact with your phone via your car’s infotainment. Our last three cars, the eldest of which was from the 2017 model year, have all had CarPlay. They make the experience of being in the car way way better. Any of the apps I really care about, and would want to interact with while on the road, have a bespoke CarPlay interface.
I literally will not buy a car that does not support CarPlay.
Most of the way through the episode, Nilay asked Wassym about CarPlay. The question was long, but the gist is this:
I hear from our readers every time I talk to a car executive that, “The reason I want CarPlay is because there’s 5,000 apps on my phone and no car OEM is ever going to support them in the built-in infotainment.”
This is when you would say, “Okay, project your phone to the center stack. The car’s driving itself. Have at it. Phone projection all day.” Do you think the tide is turning, or are you still absolutely committed to not having CarPlay in Rivian vehicles?
You can read Wassym’s full answer at the episode link, but here’s the part that stuck out to me:
The challenge with screen mirroring solutions is that they take over every single pixel in the car, and that’s not the way we see ourselves interacting with our users.
Let me help you, Wassym:

There exists a flavor of CarPlay — CarPlay Ultra — that does take over every screen of the car. Though even CarPlay Ultra has affordances for the manufacturer’s user interface to poke through. But nobody is asking for CarPlay Ultra. We’re asking for no-adjective CarPlay.
And CarPlay does not have to take up the entire screen.
Here, for example, is a photograph of my phone connected to my wife’s Volvo XC90:
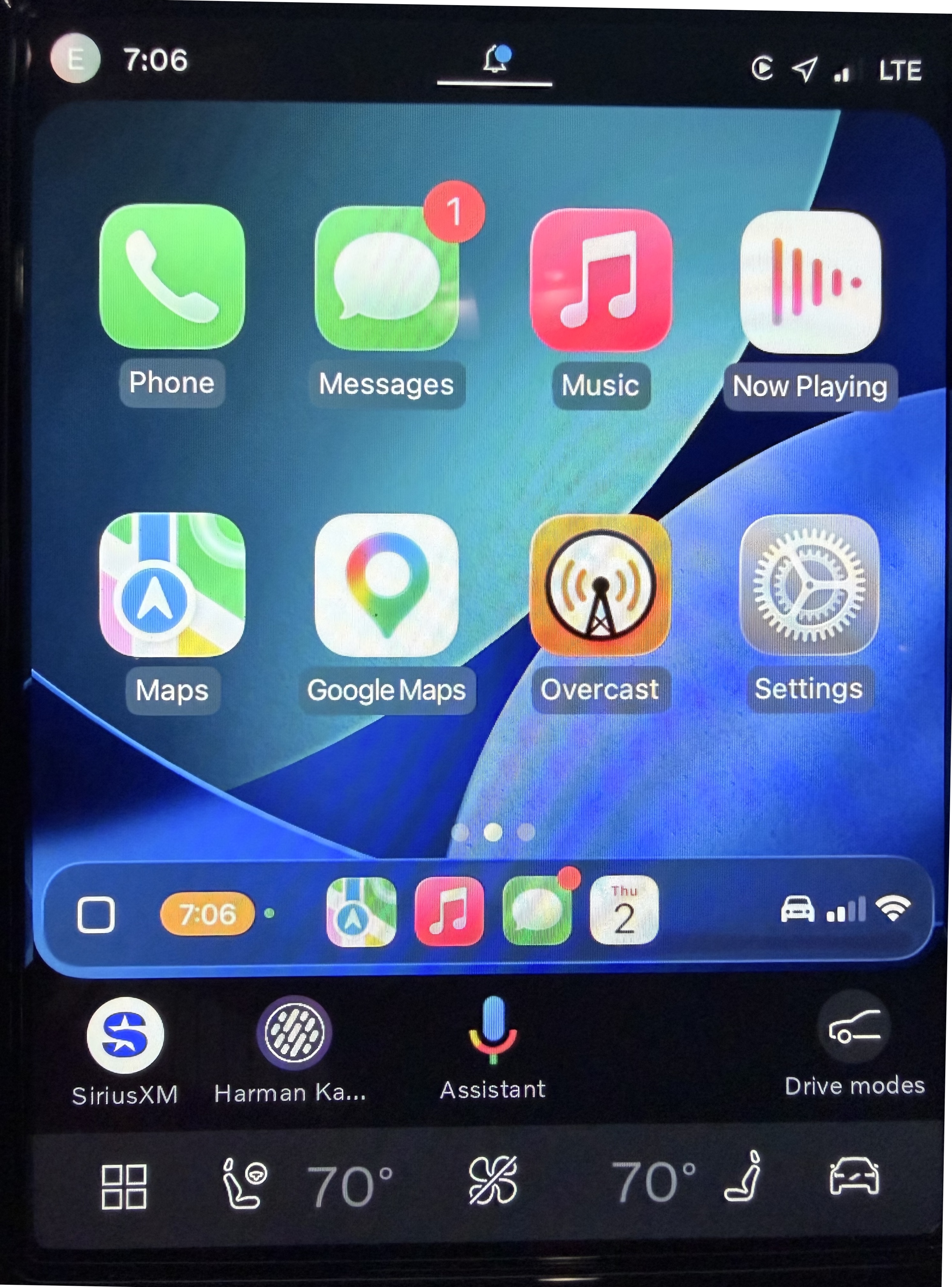
See those bits above and below the CarPlay screen? That’s Volvo UI. CarPlay literally does not know that portion of the screen exists.
So, Wassym, try again.
Let’s say — for discussion — that CarPlay did take up the entire screen. No matter what. Let’s just live in Wassym’s fantasy world for a little bit.
I still have news for you: CarPlay is optional. CarPlay is additive.
Drivers don’t have to use CarPlay!!
If Rivian’s native UI is so great, then their customers… won’t use CarPlay. It’s that simple.
Nobody is asking for CarPlay to be mandatory. We just want to have it as an option.
If Rivian’s infotainment/software is that great, that’s swell! Then Rivian drivers won’t use CarPlay.
Well, unless they wish to use one of the thousands of apps that is optimized for CarPlay, but does not have a native version that can be installed directly to their Rivian.
Like, I dunno, Overcast, for example.
“But Casey, you see, the real problem is that you can use CarPlay for navigation. And fancy cars like Rivians have some of the best automated driving technology on the market. For the driver to have the best possible experience, the car needs to know the route the driver is driving.”
A fair retort! Conveniently, Apple is addressing exactly this in iOS 27.
Ultimately, the only thing I can control is myself, and I will not buy a car that does not offer CarPlay. I enjoy Rivian so much — both from afar and as someone who has driven both a R1T and R1S — that I really thought about getting on the waiting list for a R2. And I don’t even want a SUV!
But I won’t.
Because it doesn’t support CarPlay. CarPlay support is table stakes for me.
Stop being stubborn, Rivian. Stop being so intransigent and dogmatic. CarPlay is additive, and supporting CarPlay opens you up to an additional cohort of customers. Get off your high horse and ship it.
When you do, I’ll be there, waiting. I can’t wait to get in line for a R3X. 🤤
Way back in January of 2024, Daniel at uses this asked if I would be willing to be interviewed for the site.
Nearly immediately, I told him I’d love to.
In February of this year, I finally responded to Daniel’s [very easy] questions. 🥴
While I — thankfully — did not eclipse the all-time record, I do feel badly. Thankfully, Daniel never put any pressure on me, and was a tremendous sport about the whole thing.
If you’re interested in the equipment I use to get my jobs done, you can check out my brief interview.
Callsheet version 2026.5 is slowly rolling out in the App Store. I wanted
to take a moment and highlight some changes; particularly those around Plex
integration.
Bug Fixes
First, some great bug fixes.
Due to ✨ reasons ✨, mostly of the self-created variety, Callsheet would often
show an error message with the not-particularly-actionable message cancelled.
Now, not only are the error screens far prettier, but this particular one
should happen far less often — perhaps even not at all!
Additionally, due to some poor reasoning/assumptions on my part, there were some
users who were finding their preferences around their Discover layout and/or
Region override and/or Language override were constantly getting lost. Thanks
to some beach prompting, those occurrences are finally fixed. This one
really bugged me; I’m glad to have finally gotten it nailed down!
Some other, smaller, fixes:
- Scroll position resets on wide layouts (iPad/Mac/vision) when switching between Cast & Crew
- Rarely, Callsheet would show a person as pinned who you had not pinned
- Rarely, bonus free searches would be lost when the app restarted
- Fixed a typo in English (Simplified) 🇦🇺
Improvements
Aside from the vastly improved error presentation, there are two highlight features of this release.
Pin Caching
When I wrote Callsheet, I treated iCloud as the only source for pinned items. I did not store anything locally. While this usually works, iCloud definitely has hiccups from time to time. When such a hiccup happened, my users would [justifiably!] be deeply alarmed, because Callsheet told them all their pins were gone.
Now, Callsheet caches pins locally. I still think of iCloud as the source of record, but at least now Callsheet doesn’t just “🤷♂️” if it can’t talk to iCloud.
Now Playing Improvements
Additionally, when Callsheet knows you’re actively watching a title, whenever possible, it will show how far you are through the title when looking at the details for that title. This is best shown as an example:

Here, you can see I’m watching The Hunt for Red October, and if you look at the bottom
of the poster, you can see I’m three-quarters of the way through it. Also note that
instead of showing RUNTIME, Callsheet will show ENDS AT. If you tap the ENDS AT,
you see a popover with more information about how long the film is, and how much
you’ve already watched:

I’ve already found this to be surprisingly useful when sitting on the couch watching something. I find it’s less disruptive to see how far I am through something by looking at Callsheet, rather than messing with the Apple TV remote.
Plex Connectivity
When I initially did the Now Playing support in Callsheet, I only supported Channels and Plex. This was because I was staunchly in favor of only supporting mechanisms where users would not have to do any sort of login or other authorization flow.
In the meantime, Plex gets ever-crappier, and I have slowly started
migrating to Jellyfin. Jellyfin doesn’t have [a reliable] zero-configuration
option, so I broke my rule in 2026.4.
Now that I’ve allowed myself a login flow, I figured I’d see if I could do something similar for Plex.
In Callsheet 2026.5, you can choose between two mechanisms for connecting
to Plex:
-
Passive
This is the default, and the way it’s always been. No login required. -
Active
This is 🆕, and requires you to log into Plex in a similar (but actually easier!) fashion to Jellyfin’s Quick Connect.
Both of these approaches have tradeoffs, best summarized in this table:
| Passive | Active | |
|---|---|---|
| No-login | ✅ | ❌ |
| Requires login | ❌ | ✅ |
| Shows local media | ✅ | ✅ |
| Shows remote media | ✅ | ❌ |
| Works with iOS/iPadOS Clients | ❌ | ✅ |
| Works with AppleTV Clients | ✅ | ✅ |
| Works on other networks | ❌ | ✅ |
| Actually works reliably | ❌ | ✅ |
In short, Passive mode [occasionally] works with Apple TV clients that also have
their Advertize as Client setting flipped on. And this is only if your device
and the Apple TV are on the same network, as the process starts with UDP multicast.
However, Passive mode communicates directly with Plex clients, so it can show what that client is playing back no matter what. Even if you’re playing something back from someone else’s Plex server.
Active mode says to your server “hey what am I playing right now?”. This has the advantage of working extremely reliably, and also working even if you’re not on the same network as your server. However, if you’re watching media from someone else’s server, it will not show up in Callsheet.
Generally speaking, if you’re willing to go through the login dance, I find the Active mode to be far more reliable, and also faster. Your mileage may vary.
You can find out more about all this on the Callsheet website.
Upgrading
I just hit the “go” button on version 2026.5; furthermore, for iOS/iPadOS/macOS,
I am doing a staggered release. The best way to see if you can upgrade is to
go to Callsheet in the App Store and see if you can hit an Update button.
For all six of you visionOS users, it should be available as soon as the update to the App Store’s cache finishes.
My job, nominally, is to have opinions about things. I struggle to reach a strong opinion about AI.
The other portion of my job is to write code. This part of me has no such issues reaching a conclusion.
I write this on vacation, today taking a break from the beach, and more concretely the sun’s punishing rays. During this week, I’ve been checking in on feedback from users of Callsheet from time to time. Yesterday I noticed someone having an intermittent problem that several other users have also reported on and off in the past few months. These users find that they will rearrange the order of items on the Discover screen — the main screen on Callsheet — but their changes will consistently be reverted.
Annoyingly, only some users are reporting this. Clearly, it seems to work for the lion’s share of my users. This particular bug reporter was kind, patient, and diligent. They sent a screen recording, they sent log files, and assisted me with a couple of minor follow-up requests.
Thankfully, one of those log files contained a clue I hadn’t yet noticed from other reports. My previous assessment of “welp, I guess people are just force-quitting before their preferences can be flushed to storage?” seemed like it may be wrong.
I didn’t want to really sit down and do work, but I thought I’d throw Claude Code at it to see if it could figure anything out. I gave it a pretty specific instruction, and asked it to see what it could find:
In
UserSettings.save(discoverState:), I save the user’s preferred arrangement of sections of the main/“Discover” screen on Callsheet.
Sometimes users will report that this setting is reverted to the default.
I’m completely at a loss as to how or why that could be happening. Can you
take a look and see if you have any guesses please?
It churned for a couple minutes, and came up with a theory.
I checked over the theory presented, and I’m pretty damn sure this is the bug. Presented to me, plain as day, with justification.
Claude Code did in a few minutes what I had on-and-off-again banged my head against for the better part of six months.
Humbling, yes. But also, wow; what a world developers live in now.
Later yesterday, with that win in my pocket, I thought about another, similar-yet-different issue that I had been having. Here again, I presented a specific request, and asked for help. Here again, a few minutes later, Claude found the issue.
Astonishing.
A second persistent-but-inconsistent bug squashed, I ceased furiously typing in a terminal window, and leaned back into the couch I was working upon. I was struck; I was feeling something that was familiar, but distant. I felt like I had just worked together with a coworker to solve a technical problem. It felt like I was part of a team again.
My traditional career ended in the middle of 2018; in fact, next month is the 8th anniversary of my independence. While I’m incredibly lucky to be able to work for myself, and I have astonishingly great humans as my podcasting coworkers, I often feel very alone when it comes to my development work. What I miss about having a jobby job — more than anything else — is working as part of a team to solve a tricky problem.
Claude and I are teammates now. And boy, did I miss this feeling.
It’s not the same, of course. I’d vastly prefer to have a real, human, teammate. I’d love it if Callsheet did so well that I could employ someone to work with me. It would be better in darn near every way.
But in lieu of that, this is pretty great.
Available now on visionOS, and rolling out slowly for iOS/iPadOS, is Callsheet version 2026.4. The changelist is not long, but it is mighty:
New Features
- All-new iPad landscape layout that makes far more efficient use of the space. This also applies to macOS and visionOS.
- Support for Jellyfin in the Now Playing view. Note that this does require authenticating with your Jellyfin server; see the Callsheet website for details.
- Added ability to copy a person’s name or their role/job via context menu
- Localized the “Johnny Appleseed” and “Botanist” example name/job shown in Spoiler Settings. I tried to make these fun but if I missed the mark, let me know!
Fixes
- “Hide Spoilers…” button allows tapping in the whole button, rather than just where the text is
- No longer truncate titles/names in the Discover screen whenever possible
- In rare cases, using the chevron to page between movies in a collection could fail
I wanted to discuss two of these new features.
iPad Landsape Layout
For better — but perhaps mostly for worse — I think of Callsheet as
an iOS app. I develop for the iPhone, with all other platforms getting varying
[small] amounts of my attention. I don’t say this with pride, but rather to
excuse explain why it is the iPad layout was so janky for so long. I just
kept having other, bigger, fish to fry.
In addition to prioritizing other things above redesigning the iPad layout, I also… wasn’t sure what to do. I went through a few ideas, but they all died on the vine. Some were too difficult to implement because they broke assumptions that SwiftUI makes about the way you use SwiftUI controls. Some were reasonably easy to implement, but I found they didn’t really improve the way the app felt.
Where I eventually landed was to switch the landscape layout to a sorta-kinda two pane layout. The left side has what I had previously considered the “above the fold” content; the right side has the cast/crew lists.
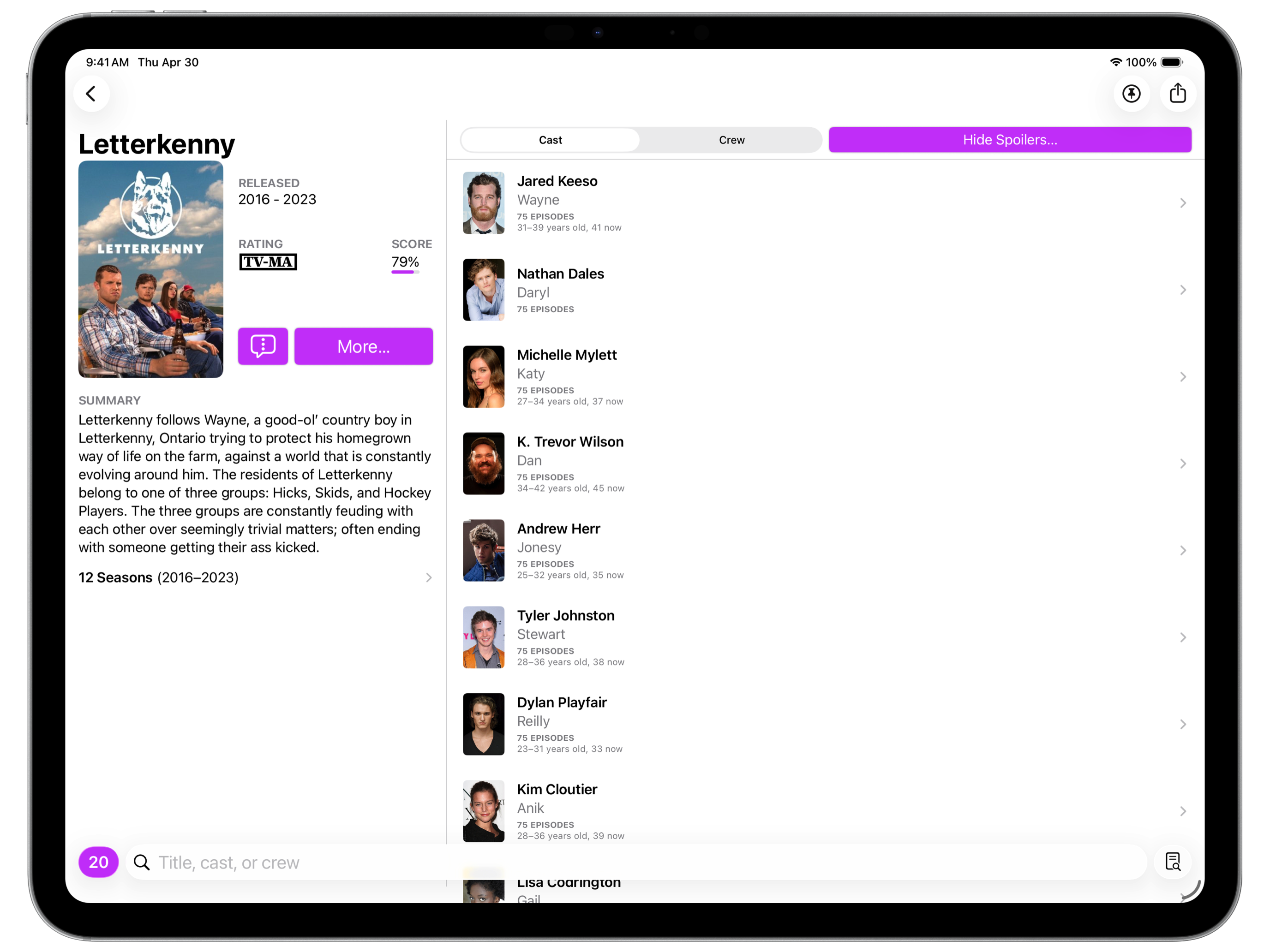
I feel like this works pretty well, and still feels like Callsheet. I may refine it more in the future, but I’m way way happier with how this feels and works than I was with the embarrassment that preceded it.
Jellyfin Support in Now Playing
When I first started integrating Plex into Callsheet — Callsheet can show what was currently playing on a local Plex client — I was convinced that doing any sort of authentication/login/authorization/whatever flow was too onerous for a user. I wanted to limit myself only to what could be discovered without any sort of logging in to anything.
I continued this self-imposed rule when integrating with Channels.
Over the last year or so, I’ve become ever-less-enthusiastic about Plex. While my needs from Plex have not changed at all, their interest in serving those needs has diminished dramatically. As such, I’ve long considered if I should find an alternative.
This is also exacerbated by Plex using an absolutely bananas and deeply unreliable mechanism for sharing playback information. It almost never works, and I sorta regret even including it in Callsheet.
A couple months back, I finally gave in, and installed Jellyfin, which is running as a peer of Plex on the same Mac mini.
I’m not here to review Jellyfin in this post, but the ultra-short version is, it’s pretty great, as long as you don’t need to share your content with anyone, and as long as you find a third-party player you like. (For me, I really like SenPlayer.)
Now that I’m using Jellyfin for the consumption of non-ephemeral media, I wanted to see that information in Callsheet. So, I started down the path of seeing what I could glean from my Jellyfin server without having any sort of login dance.
That expedition ended quickly. In failure. Jellyfin doesn’t offer any sort of now playing information if you don’t have some sort of authentication with the server.
However, I was able to discover a pretty reasonable alternative.
Jellyfin has the concept of Quick Connect, in which the user flow is:
- The user specifies the server URL
- The client app gives the user a six-digit Quick Connect code
- The user enters that code on the Jellyfin management website
(I should note the client app flow is a fair bit more complicated, but well within reason.)
While far from auto-discovery, this is far from onerous.
So, that’s what I’ve done.
In Callsheet, if you go to Settings → Persnickety Preferences →
Integrations, there’s a section for Jellyfin. You can enter your
server URL, get a Quick Connect code, and then open a web browser
right there to enter that code in your server’s administration panel.
In principle, this dance should only need to happen once; Callsheet will retain the connection to Jellyfin for as long as your server allows.
Interestingly, if you’re a Tailscale person, and you enter
your 100.x.y.z or x.ts.net address as your server, the Jellyfin
integration is actually the only one of the three that works remotely.
Plex and Channels only work if Callsheet is on the same network as the
playback client.
I’m pretty proud of both of these features, but if you have issues with
either, please feel free to use the in-app feedback feature in Settings
to send me thoughts/questions/complaints/etc. Using the in-app feature
will automatically include a log file that is often helpful in diagnosing
issues.
Last week was spring break, which included a brief trip to show my family my old stomping grounds. As such, I didn’t have a chance to call out this fun appearance I made on The Verge’s and David Pierce’s excellent newsletter, Installer.
My two home screens were featured; as mentioned here a while ago, I have started using only two, and searching for anything else I may need.
I’m really honored to have been asked; I’m also pleased with how it turned out. 😊 If you’re not an Installer subscriber, you should be. David’s got an incredible knack for finding and surfacing cool stuff.